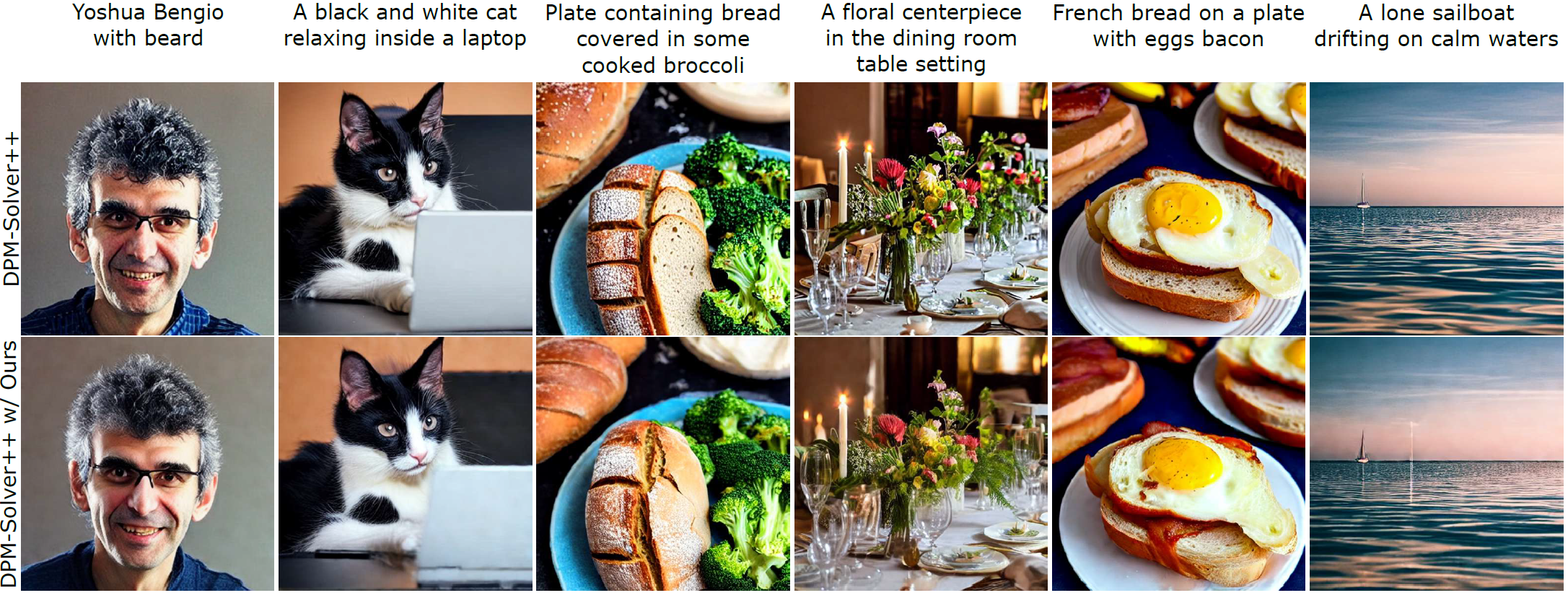
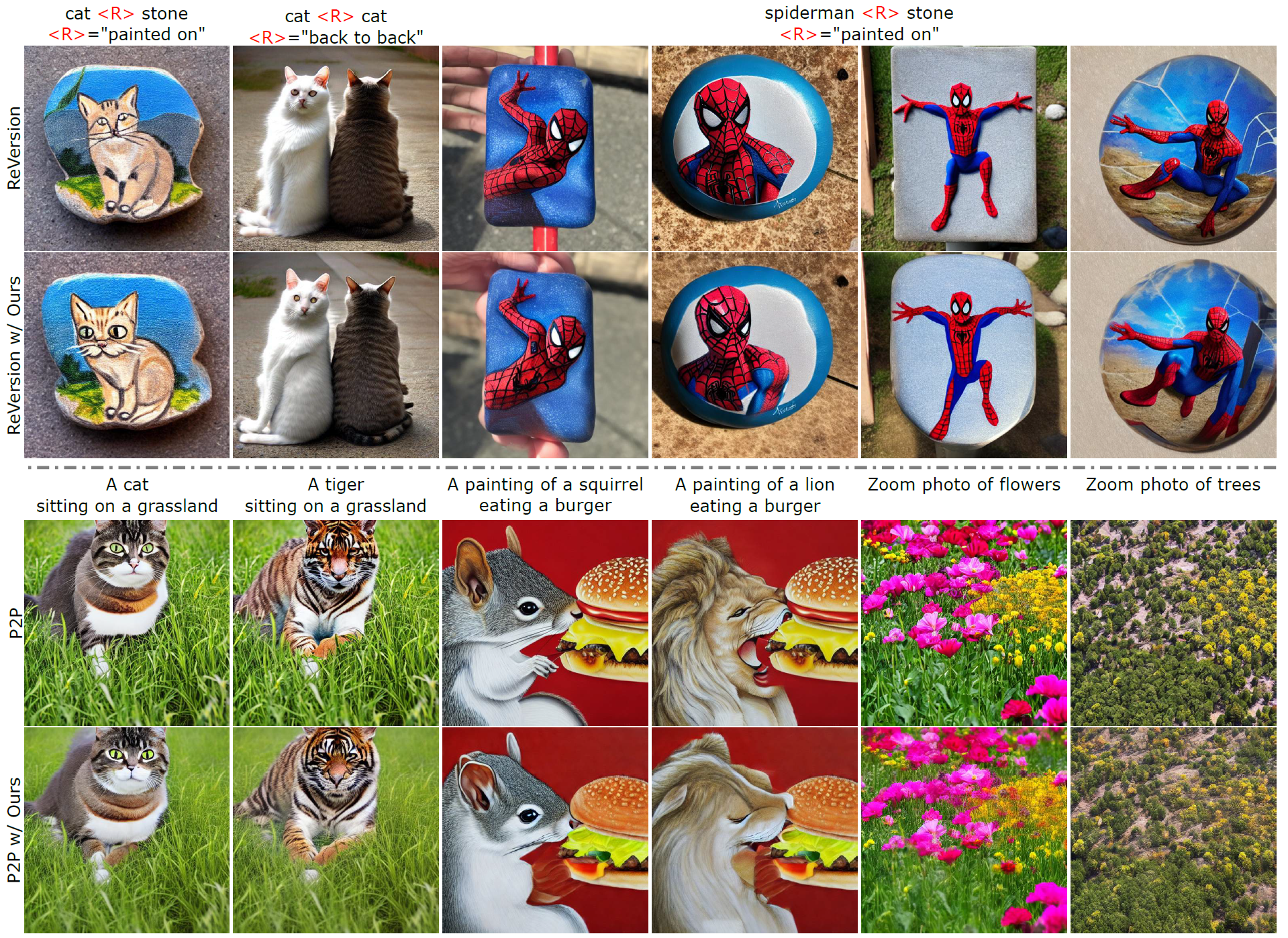
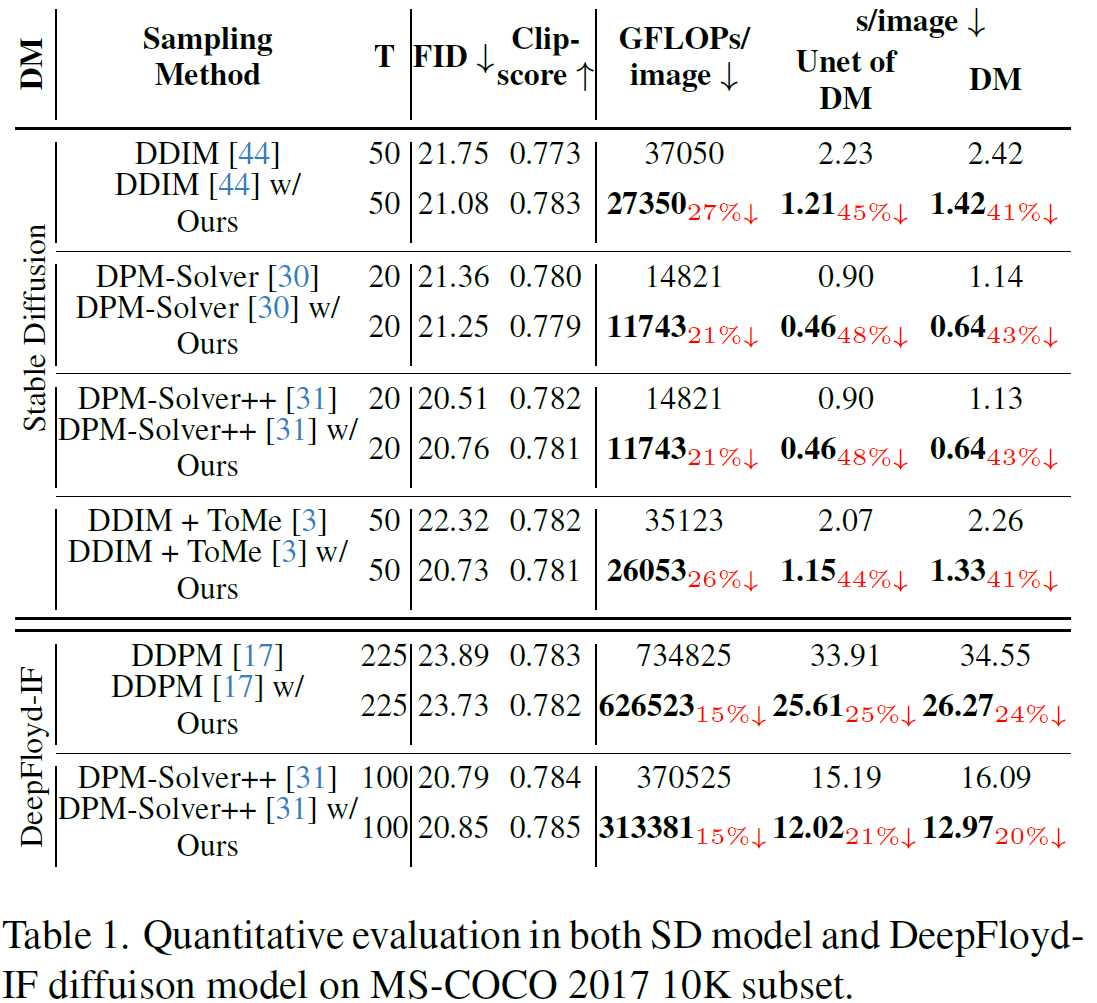
One of the key components within diffusion models is the UNet for noise prediction. While several works have explored basic properties of the UNet decoder, its encoder largely remains unexplored. In this work, we conduct the first comprehensive study of the UNet encoder. We empirically analyze the encoder features and provide insights to important questions regarding their changes at the inference process. In particular, we find that encoder features change gently, whereas the decoder features exhibit substantial variations across different time-steps. This finding inspired us to omit the encoder at certain adjacent time-steps and reuse cyclically the encoder features in the previous time-steps for the decoder. Further based on this observation, we introduce a simple yet effective encoder propagation scheme to accelerate the diffusion sampling for a diverse set of tasks. By benefiting from our propagation scheme, we are able to perform in parallel the decoder at certain adjacent time-steps. Additionally, we introduce a prior noise injection method to improve the texture details in the generated image. Besides the standard text-to-image task, we also validate our approach on other tasks: text-to-video, personalized generation and reference-guided generation. Without utilizing any knowledge distillation technique, our approach accelerates both the Stable Diffusion (SD) and the DeepFloyd-IF models sampling by 41% and 24% respectively, while maintaining high-quality generation performance.





@article{li2024faster,
title={Faster diffusion: Rethinking the role of the encoder for diffusion model inference},
author={Li, Senmao and Hu, Taihang and van de Weijer, Joost and Shahbaz Khan, Fahad and Liu, Tao and Li, Linxuan and Yang, Shiqi and Wang, Yaxing and Cheng, Ming-Ming and others},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={85203--85240},
year={2024}
}